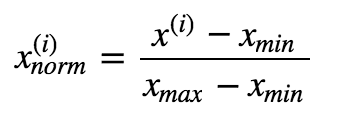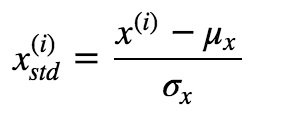import pandas as pd
df1 = pd.DataFrame([['male', '178'],['female', '162']], columns=['gender','height (cm)'])
| gender | height (cm) | |
|---|---|---|
| 0 | male | 178 |
| 1 | female | 162 |
因身高有連續性,標示在空間裡沒問題;若性別改成male:0,female:1,則導致不同性別對原點的距離不同。相同的若顏色在分類上也會出現一樣的問題。
解決方式利用One-Hot Encoding來編碼。
pd.get_dummies(df1['gender']) #在pandas中用get_dummies這個函式
| female | male | |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 1 | 0 |
female編碼成[0,1],male編碼成[1,0];不要把它想成二進位,它們都沒有量,只是標示而已。
練習合併
onehotEncode = pd.get_dummies(df1['gender'], prefix='gender') #先產生一個df放編碼後的表格
onehotEncode
| gender_female | gender_male | |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 1 | 0 |
再把原來的gender那欄先刪掉
df2 = df1.drop('gender',1)
df2
| height (cm) | |
|---|---|
| 0 | 178 |
| 1 | 162 |
再和One-Hot Encoding過的onehotEncode合併
df2 = pd.concat([onehotEncode,df2],axis=1)
df2
| gender_female | gender_male | height (cm) | |
|---|---|---|---|
| 0 | 0 | 1 | 178 |
| 1 | 1 | 0 | 162 |
大工告成,可喜可賀